Problème
Lors du développement d'une application en Java (ou dans un autre langage), nous utilisons très régulièrement des Collections pour stocker des données.
Cependant, chaque implémentation de cette interface réponds à certaines problématiques, et donc ce choix devient important lors de la phase d'optimisation de l'application.
Mon but fut alors de comparer le temps d'exécution et d'utilisation mémoire de différentes collections afin de voir laquelle est la plus performante.
Pour ce faire, j'ai testé 3 opérations différentes :
- L'insertion d'un élément
- La présence d'un élément
- La suppression d'un élément
Pour réaliser mes tests, j'ai choisi 3 classes implémentant l'interface ICollection qui sont :
ArrayListLinkedListHashSet
Afin d'observer les différences de temps d'exécution et d'utilisation mémoire, j'ai choisi de faire varier les paramètres suivants afin de pouvoir choisir laquelle répond le mieux à mon problème, et dans quels circonstances :
- Le nombre de tests par opération
- La taille de la structure
Dispositif expérimental
Application
Usage : java Main <structure> <longueur> <operation> <valeur associée à l'opération>structure :
LinkedList => LinkedList
HashSet => HashSet
Autres écritures => ArrayList
operation:
Présence => Contains
Suppression => Remove
Autres écritures => Add
valeur associée :
Présence => index à tester
Suppression => index à supprimerUsage : ./script.sh | tee ../data/perf.datUsage : ./graphique.R
(vérifier que le fichier data/perf.dat à été rempli à l'aide du script shell)Environnement de test
J'ai fais nos tests sur les serveurs dédiés aux élèves de l'IUT, voici le résumé des informations tirées de /proc/cpuinfo
model name : QEMU Virtual CPU version 0.13
cpu MHz : 2294.246
cache size : 512 KB
cpu cores : 1Description de la démarche systématique
Description de la démarche systématique et de l'espace d'exploration pour chaque paramètres.
./script.sh | tee ../data/perf.dat
-> compile les fichiers .java nécéssaires à l'éxécution du Main
-> Execute la batterie de tests grâce aux fichiers java (compilé)
-> ./graphique.R : créé les deux graphiques souhaitésRésultats préalables
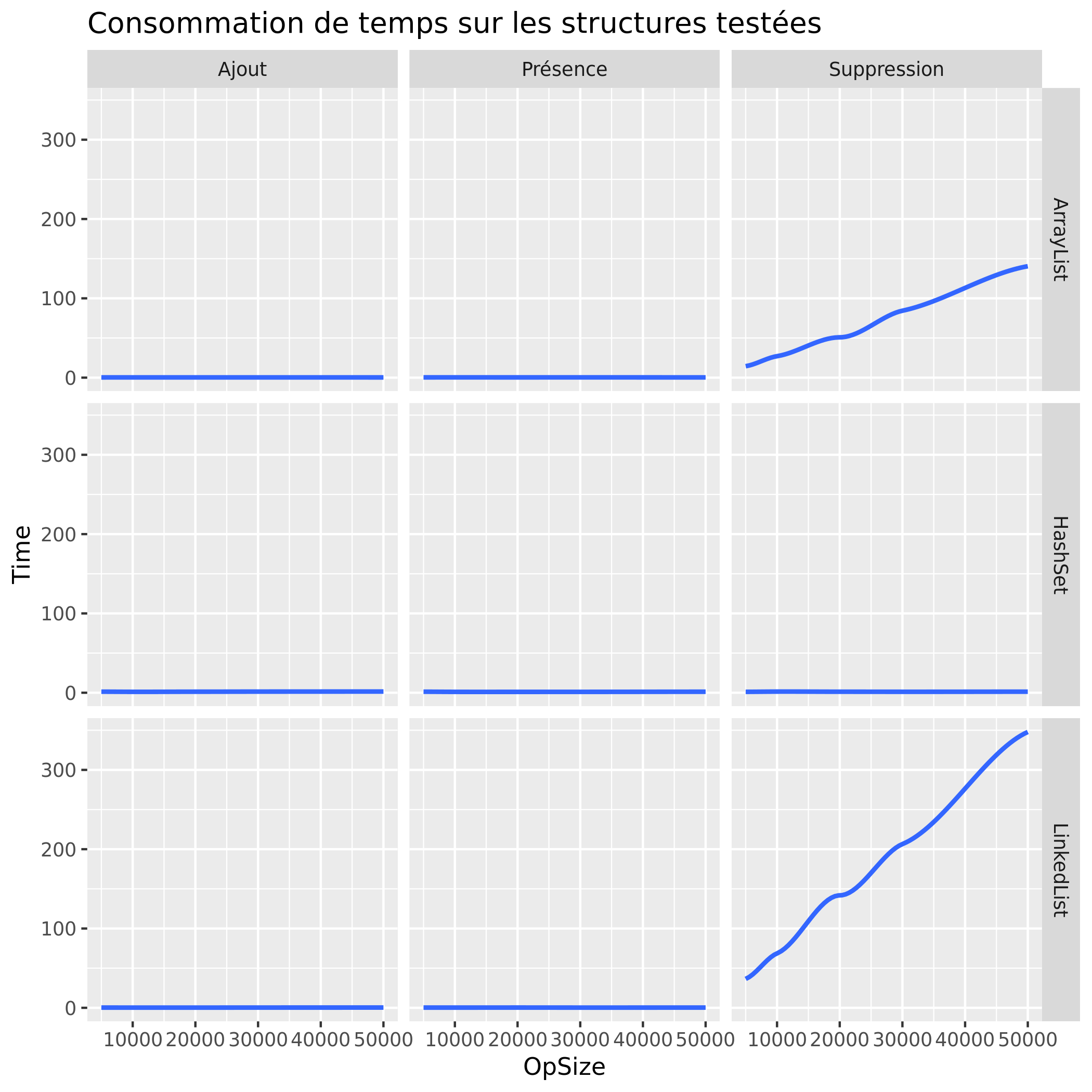
Temps d'exécution
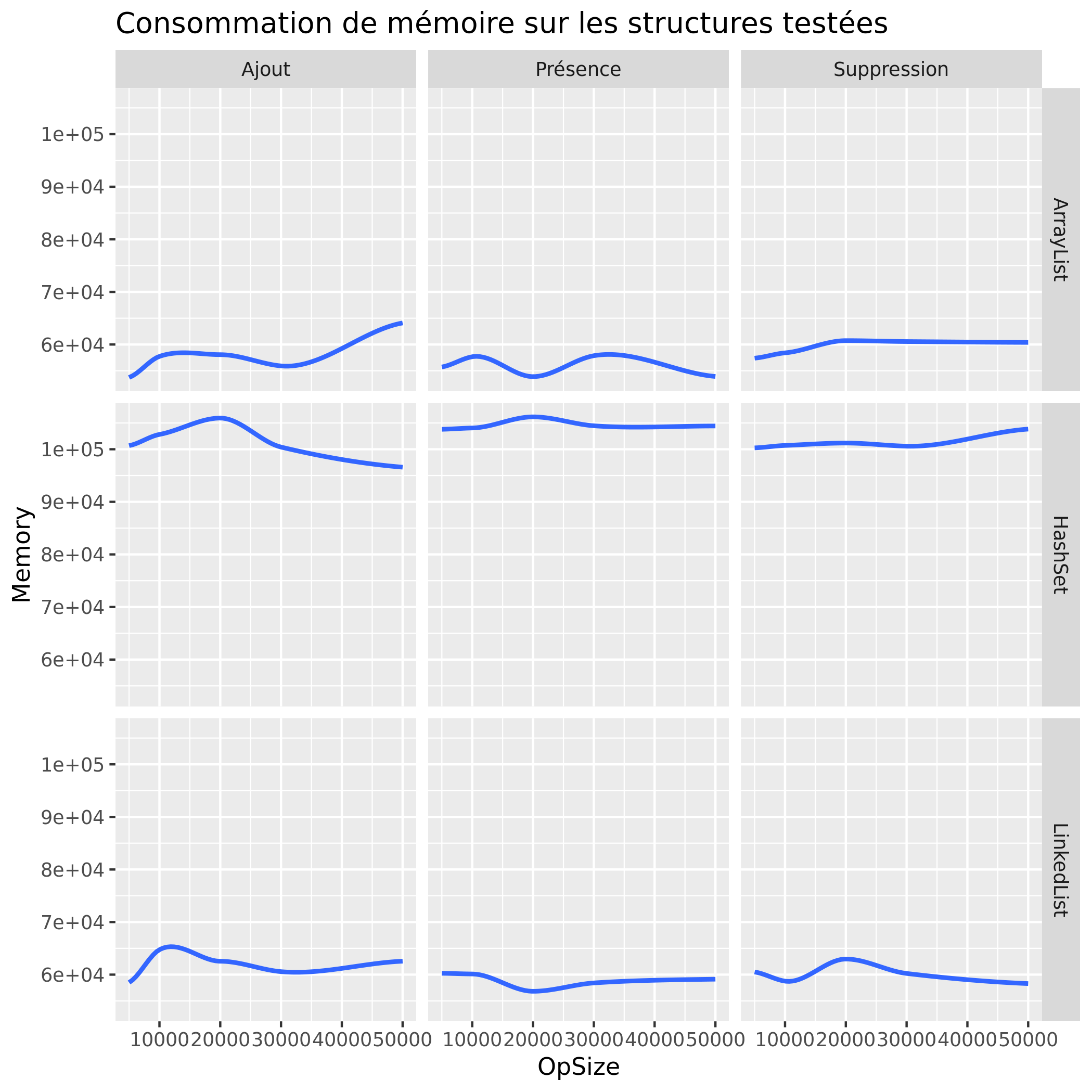
Consommation mémoire
Analyse des résultats préalables
On remarque ici une nette différence de temps lors de l'utilisation d'une Hashset dans n'importe quelle situation et pourtant, à travers l'étude de la mémoire utilisé on voit que la Hashset et plus gourmand, et donc répondras à une demande de rapidité et non de consommation minimale.
De plus on voit aussi que l'ArrayList est un peu plus rapide que la LinkedList peut importe la situation, sans pour autant demander de la mémoire supplémentaire. Il faut donc privilégier l'ArrayList à la LinkedList dans toutes situations.
Discussion des résultats préalables
Le HashSet est beaucoup plus rapide que les deux autres structures étudiées pour tous les tests car les valeurs qu'il contient sont triées. Cependant elle se retrouve beaucoup plus gourmande pour ces opérations et doit donc être utilisée pour répondre à une problématique de rapidité plûtot que d'optimisation mémoire.
Quant à la LinkedList, elle réside sur un principe de liste chaînée et donc de maillons, c'est donc pour cela qu'elle devient rapidement gourmande par rapport aux autres structures notamment lorsqu'elle atteint une taille assez conséquente.
Enfin, l'ArrayList est une liste polyvalente alliant un temps d'éxecution relativement faible, sans pour autant devenir gourmande en mémoire, ce qui explique qu'elle soit couramment utilisé, sans compter son principe de fonctionnement trivial.
Etude approfondie
Hypothèse
Dans les tests précédents, nous avons remarqué que les performances de la structure HashSet sont vraiment intéressantes et rapides. malgré sa consommation de ressources supplémentaires, la durée très courte d'éxecution rends la structure la plus efficace sur de courtes utilisations. Mais alors notre génération de valeurs fut aléatoire, et nous pouvons nous demander comment les structures réagissent lors de l'utilisation de tableaux triées. Nous posons donc l'hypothèse que les ressources mémoire des structures testées (HashSet,ArrayList,LinkedList) seront réduites dans le cadre de l'utilisation de tableaux triés.
Nous utiliserons des structures remplies de 500.000 éléments, pour pouvoir comparer nos xpérimentations avec nos valurs précédentes.
Protocole expérimental de vérification de l'hypothèse
Usage : java Hypothese <structure> <longueur> <operation> <valeur associée à l'opération>structure :
LinkedList => LinkedList
HashSet => HashSet
Autres écritures => ArrayList
operation:
Présence => Contains
Suppression => Remove
Autres écritures => Add
valeur associée :
Présence => index à tester
Suppression => index à supprimerUsage : ./script.sh Hypothese | tee ../data/perf_hypothese.datUsage : ./graphique_hypothese.R
(vérifier que le fichier data/perf_hypothese.dat à été rempli à l'aide du script shell)Nous avons juste changer le remplissage des différentes structures pour la rendre ordonnée et croissante :
public static Collection add(Collection c, int size) {
for (int i = 0; i < size; i++) {
c.add(i);
}
return c;
}Résultats expérimentaux
Temps d'exécution

Consommation mémoire
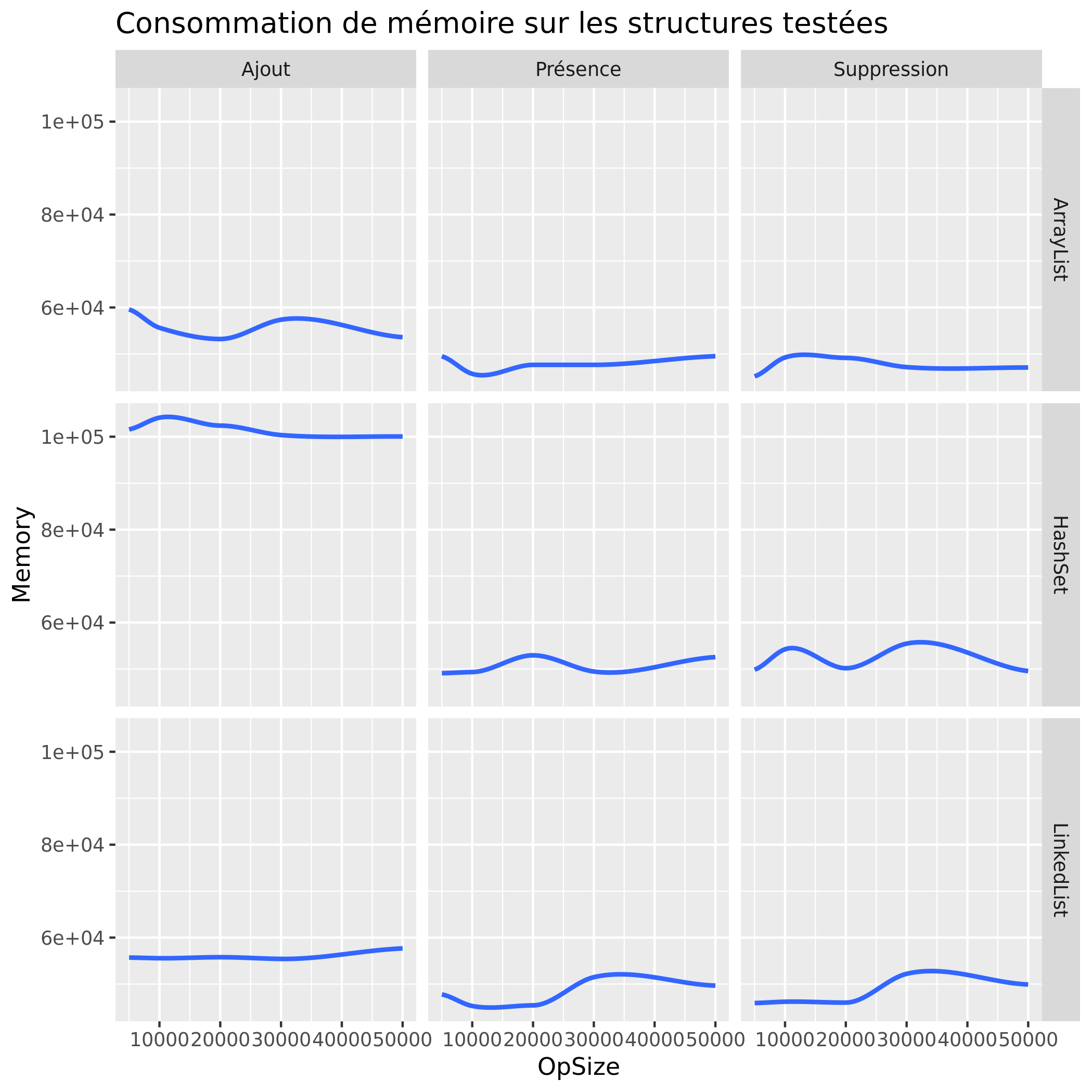
Analyse des résultats expérimentaux
Nous remarquons déjà par les axes de nos graphes qu'au niveau du temps de traitement, les plus grands temps sont passés de plus de 5 min à moins de 30 secondes, pour toutes les structures testées. plus précisement :
`ArrayList`:
Ajout : Temps négligeable => Temps négligable
Présence : 0 sec => 10 sec en moyenne
Suppression : Croissante faible avec le nombre de requete => Temps négligable
`LinkedList`:
Ajout : Temps négligeable => Temps négligable
Présence : Temps négligeable => 25 sec en moyenne
Suppression : Croissante forte avec le nombre de requete => Temps négligableDiscussion des résultats expérimentaux
ArrayList :
Vitesse :
- L'ajout d'un valeur n'est pas affecté par l'ordre de la liste car c'est totalement indépendant à la nature de la liste.
- La présence en revanche, est bien plus affecté car dans le cadre d'une liste ordonnée trouver une valeur revient à trouver son indentation ce qui prendras bien plus de temps.
- Enfin le temps de suppression s'est effondrée car il est bien plus rapide de supprimer une valeur égale à son indentation, surtout pour une structure basée sur un tableau .
Mémoire :LinkedList:
Vitesse :
Toutes les études de vitesses sont équivalentes avec l'ArrayList mais, de part le chaînage en maillon de cette structure, les écarts sont bien plus grands, c qui explique la différence de 15 secondes sur la partie de présence
Mémoire :Hashset:
Vitesse :
Mémoire :